智能文檔處理(IDP)是利用人工智能技術(shù),自動(dòng)從復(fù)雜的非結(jié)構(gòu)化和半結(jié)構(gòu)化文檔中抽取關(guān)鍵數(shù)據(jù),并將其轉(zhuǎn)換成結(jié)構(gòu)化數(shù)據(jù)的技術(shù)。IDP又稱(chēng)為認(rèn)知數(shù)據(jù)處理(Cognitive Data Processing)或智能數(shù)據(jù)捕獲(Intelligent Data Capturing)技術(shù)。眾所周知,商業(yè)數(shù)據(jù)是企業(yè)數(shù)字化轉(zhuǎn)型的核心。然而,現(xiàn)實(shí)中80%的商業(yè)數(shù)據(jù)都是非結(jié)構(gòu)化格式,比如郵件、圖片和各種企業(yè)文檔,其中非結(jié)構(gòu)化文檔占據(jù)了絕大多數(shù)。據(jù)統(tǒng)計(jì),到2025年,全球企業(yè)數(shù)據(jù)總量將達(dá)到175ZB。借助于IDP技術(shù),企業(yè)能夠?qū)崿F(xiàn)文檔自動(dòng)化處理、文檔語(yǔ)義理解、智能審核和數(shù)據(jù)智能分析等方面的功能,提升企業(yè)用戶文檔處理的效率和質(zhì)量,為企業(yè)降本增效。從文檔的結(jié)構(gòu)特點(diǎn)上,我們可以將現(xiàn)實(shí)世界的文檔劃分為結(jié)構(gòu)化、半結(jié)構(gòu)化和非結(jié)構(gòu)化三種類(lèi)型。對(duì)應(yīng)到版式特征上,分別是固定版式、多版式和開(kāi)放版式三種類(lèi)型。結(jié)構(gòu)化文檔具有版式固定的特點(diǎn),同一類(lèi)型不同樣本之間沒(méi)有差異,如固定版式的信息采集表、申請(qǐng)文件等。半結(jié)構(gòu)化文檔版式相對(duì)固定,或稱(chēng)為多版式文檔,同一類(lèi)型不同樣本之間關(guān)鍵內(nèi)容相同,但是往往內(nèi)容出現(xiàn)的位置卻不同,如不同供應(yīng)商采購(gòu)的送貨單,每個(gè)供應(yīng)商都不同,但是其關(guān)鍵內(nèi)容都包含訂單號(hào)、商品信息等。非結(jié)構(gòu)化文檔又稱(chēng)為開(kāi)放版式文檔,通常沒(méi)有顯著的版式特征,幾乎是純文本表達(dá),雖然表達(dá)的內(nèi)容相同,但是表達(dá)方式卻差異很大。常見(jiàn)的如合同、簡(jiǎn)歷、招標(biāo)文件等。對(duì)于結(jié)構(gòu)化和半結(jié)構(gòu)化文檔,由于版式相對(duì)固定,當(dāng)前行業(yè)內(nèi)普遍的做法是通過(guò)模板或深度學(xué)習(xí)模型的方法,完成分類(lèi)和信息抽取等自動(dòng)化處理,已經(jīng)能夠解決大多數(shù)應(yīng)用場(chǎng)景的問(wèn)題。但是,開(kāi)放版式文檔,由于其天然的諸多難點(diǎn),給智能文檔處理帶來(lái)了很大的困難。如下表,是我們歸納的開(kāi)放版式文檔處理的主要難點(diǎn)。
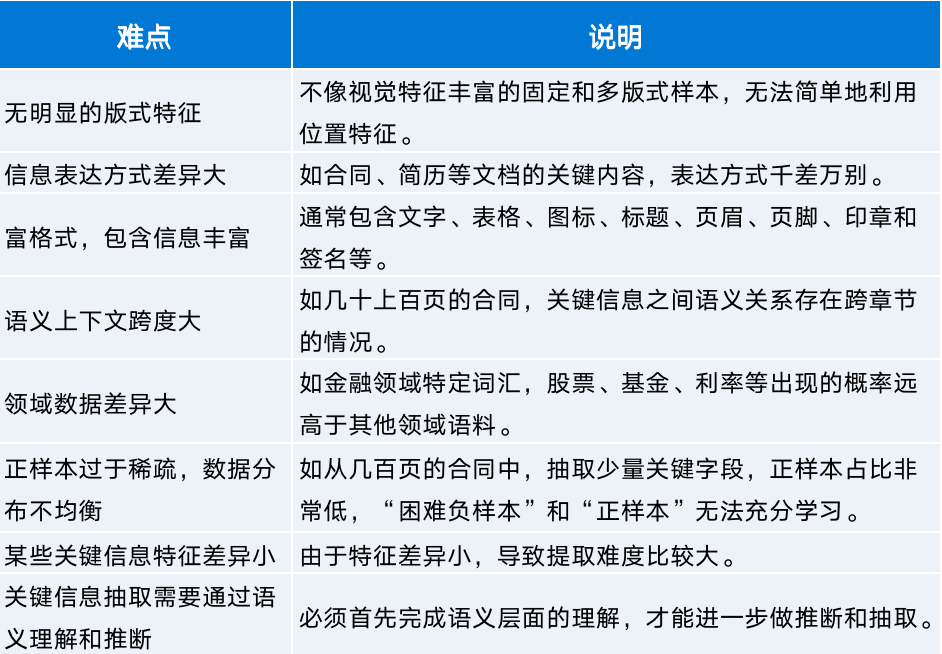
表1 開(kāi)放版式文檔特點(diǎn)
如表1,相比于純文本或固定和多版式文檔,開(kāi)放版式文檔處理具有諸多難點(diǎn)。因此,智能文檔處理過(guò)程必須綜合應(yīng)用計(jì)算機(jī)視覺(jué)(CV)、光學(xué)字符處理(OCR)、文檔解析、自然語(yǔ)言處理(NLP)和文檔信息抽取等關(guān)鍵技術(shù),才能更好地實(shí)現(xiàn)自動(dòng)化和智能化處理。計(jì)算機(jī)視覺(jué)(CV)技術(shù)
CV技術(shù)主要是對(duì)于文檔圖像進(jìn)行各種圖像處理,常見(jiàn)如圖像去噪聲、去干擾、圖像增強(qiáng)、圖像壓縮、圖像分割等。其處理目的主要是為后續(xù)OCR環(huán)節(jié)提供高質(zhì)量的圖像輸入,以提升OCR的性能。同時(shí),利用圖像檢測(cè)和分割等技術(shù),可以實(shí)現(xiàn)文檔物理版面解析。
OCR是將紙質(zhì)文檔、圖片等非數(shù)字化文件中的文字內(nèi)容轉(zhuǎn)換為數(shù)字化格式的技術(shù)。當(dāng)前主流實(shí)現(xiàn)上,借助表格識(shí)別、印章識(shí)別、勾選和二維碼識(shí)別等技術(shù),在OCR環(huán)節(jié)可以實(shí)現(xiàn)圖像中所有通用對(duì)象(文字、表格、印章、勾選、二維碼、簽名等)的統(tǒng)一識(shí)別和輸出,作為后續(xù)智能化文檔處理環(huán)節(jié)的輸入。
文檔解析是在文檔協(xié)議解析或OCR處理的結(jié)果上,通過(guò)版面分析、表格解析等技術(shù),實(shí)現(xiàn)文檔物理和邏輯結(jié)構(gòu)的解析,得到文檔內(nèi)容的統(tǒng)一表示。以此作為進(jìn)一步文檔分類(lèi)、信息抽取和文檔比對(duì)等處理的輸入。IDP通常需要能夠支持所有格式的文檔輸入,包括圖片、PDF、Word、OFD等,因此,文檔解析環(huán)節(jié)需要能夠解析以上各種格式的輸入文件,將其轉(zhuǎn)換成統(tǒng)一的表示形式,如JSON文件。
NLP是一種利用計(jì)算機(jī)技術(shù)對(duì)自然語(yǔ)言進(jìn)行分析和處理的技術(shù),常見(jiàn)的NLP任務(wù)包括分詞、詞性標(biāo)注、句法分析、語(yǔ)義分析、文本分類(lèi)、信息抽取、文檔摘要、情感分析等。IDP中主要使用的NLP技術(shù)包括文本分類(lèi)、文本信息抽取、語(yǔ)義理解等。通常的做法是將OCR輸出或文檔協(xié)議解析后的所有文本塊進(jìn)行拼接,得到文本序列,再通過(guò)文本分類(lèi)、信息抽取等技術(shù),實(shí)現(xiàn)文檔的分類(lèi)和信息抽取。另外,通過(guò)NLP技術(shù),也可以對(duì)文檔進(jìn)行自動(dòng)摘要、情感分析和智能問(wèn)答等處理。
相比于純文本,文檔的最大特點(diǎn)是其富格式特點(diǎn)。因此,文檔中信息抽取必須依賴(lài)于版面位置等視覺(jué)特征,比如從文檔中的圖表或表格中抽取信息,或者從特定版面位置區(qū)域的結(jié)構(gòu)化信息塊中抽取信息。相比于簡(jiǎn)單地從大段文本序列中做信息抽取,文檔信息抽取技術(shù)難度更大。
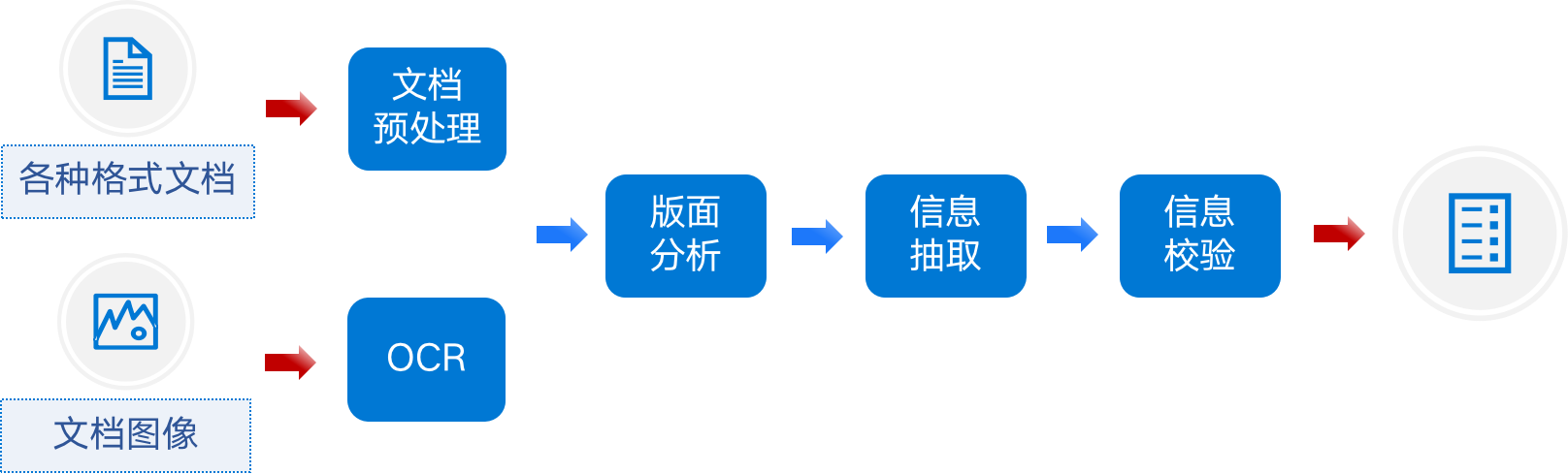
圖1 智能文檔處理流程
該步驟主要針對(duì)Word、PDF等文檔協(xié)議進(jìn)行解析處理。
通過(guò)通用OCR識(shí)別模型,對(duì)輸入的文檔圖像上的文字、印章、簽名、表格等通用要素進(jìn)行識(shí)別,得到文本和位置,以及表格結(jié)構(gòu)化數(shù)據(jù)。
利用版面分析技術(shù),定位出文檔圖像上所有的標(biāo)題、段落、表格、圖表、頁(yè)眉、頁(yè)腳等版面信息。再利用標(biāo)題和段落等信息,做文檔邏輯結(jié)構(gòu)分析,得到文檔結(jié)構(gòu)。
基于版面和目錄分析的結(jié)果,結(jié)合文檔協(xié)議解析或OCR的結(jié)果,利用自然語(yǔ)言處理等技術(shù),進(jìn)行文檔關(guān)鍵信息抽取。
利用預(yù)設(shè)的規(guī)則,對(duì)抽取出的信息進(jìn)行校驗(yàn),包括數(shù)據(jù)格式檢查、預(yù)設(shè)的審閱規(guī)則檢查等。主要的智能文檔處理應(yīng)用場(chǎng)景包括:
通過(guò)智能文檔處理技術(shù),可以對(duì)大量文檔進(jìn)行分類(lèi)和標(biāo)簽化,從而實(shí)現(xiàn)文檔的快速檢索、內(nèi)容推薦和歸檔處理等功能。
智能文檔處理可以幫助從文檔中抽取關(guān)鍵信息,如關(guān)鍵的短語(yǔ)、實(shí)體、事件等。這些信息在知識(shí)圖譜構(gòu)建、智能搜索、智能比對(duì)、智能問(wèn)答等應(yīng)用場(chǎng)景中具有重要的價(jià)值。
利用智能文檔處理技術(shù),可以對(duì)文檔進(jìn)行自動(dòng)摘要,生成簡(jiǎn)潔、精煉的摘要內(nèi)容。此外,還可以根據(jù)用戶輸入的關(guān)鍵詞或短語(yǔ)生成特定主題的文章,以滿足用戶需求。
通過(guò)智能文檔處理技術(shù),可以構(gòu)建智能問(wèn)答系統(tǒng),為用戶提供及時(shí)準(zhǔn)確的文檔內(nèi)容信息。未來(lái)隨著大模型等人工智能技術(shù)的不斷發(fā)展,智能文檔處理將會(huì)在各個(gè)行業(yè)的應(yīng)用場(chǎng)景中不斷普及化。賽博智能學(xué)習(xí)平臺(tái)智能文檔處理賽博智能學(xué)習(xí)平臺(tái)定位于一體化機(jī)器學(xué)習(xí)訓(xùn)練平臺(tái),集成了對(duì)于結(jié)構(gòu)化和非結(jié)構(gòu)文檔的智能化處理功能,包括智能文檔分類(lèi)、文檔解析和文檔信息抽取等。能夠支持合同、法律文書(shū)、招投標(biāo)文件等各種開(kāi)放版式長(zhǎng)文檔的智能化處理。基于平臺(tái)自定義模板和自訓(xùn)練模型能力,通過(guò)現(xiàn)場(chǎng)模板定制、模型標(biāo)注訓(xùn)練的方式,能夠形成即時(shí)可用的文檔AI能力。如下圖,是賽博智能學(xué)習(xí)平臺(tái)智能文檔處理的基本流程。
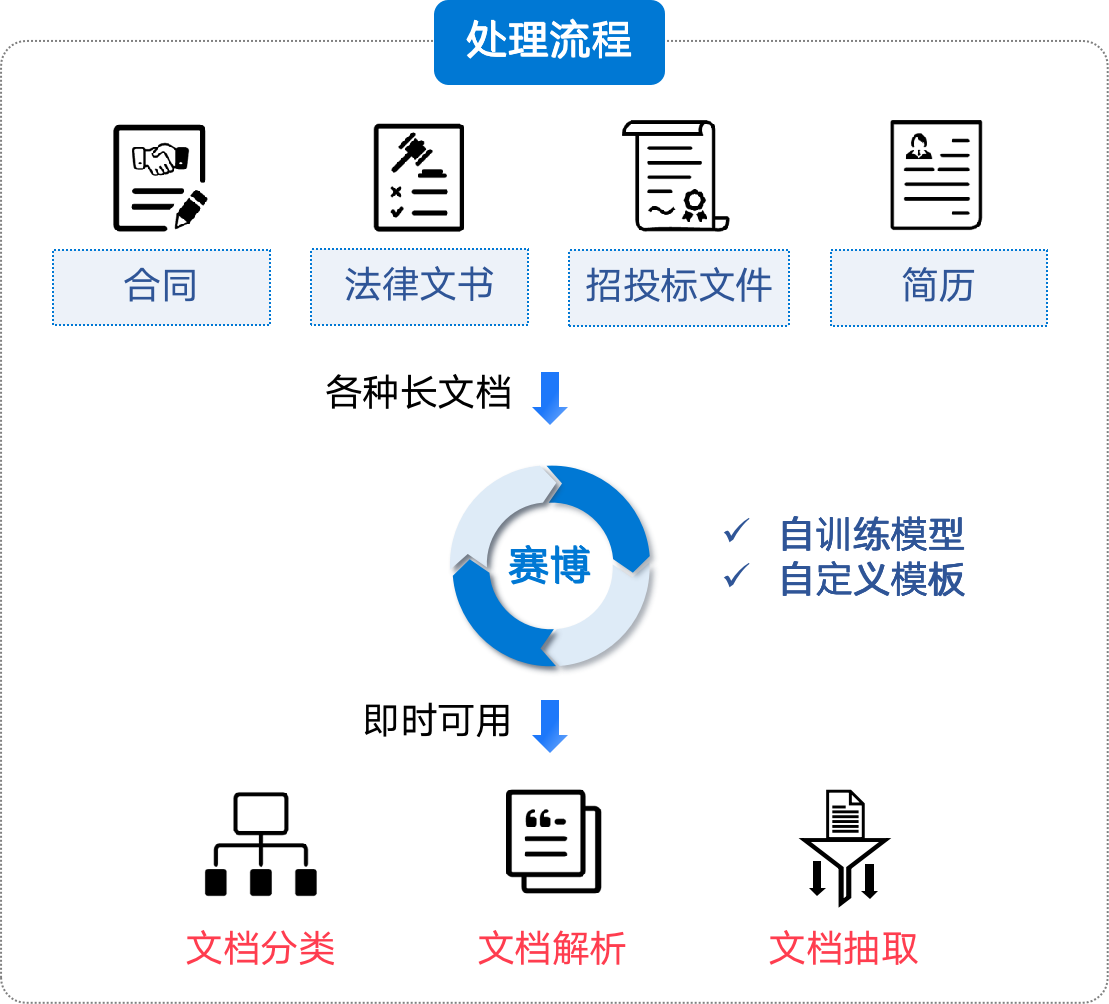
圖2 賽博智能學(xué)習(xí)平臺(tái)智能文檔處理流程
未來(lái),易道博識(shí)將繼續(xù)針對(duì)金融、能源、通信等行業(yè)客戶,在業(yè)務(wù)運(yùn)營(yíng)、審核和監(jiān)督管理、信息檢索和風(fēng)險(xiǎn)管理等場(chǎng)景下,圍繞數(shù)字化、自動(dòng)化和智能化需求,依托賽博智能學(xué)習(xí)平臺(tái),為企業(yè)打造強(qiáng)大AI底座,助力企業(yè)建設(shè)基于AI模型全生命周期的標(biāo)準(zhǔn)化、一體化生產(chǎn)運(yùn)營(yíng)體系。賽博智能學(xué)習(xí)平臺(tái)以私有化部署、現(xiàn)場(chǎng)訓(xùn)練的形式滿足客戶對(duì)數(shù)據(jù)安全要求,通過(guò)與業(yè)務(wù)系統(tǒng)深度融合,滿足各業(yè)務(wù)場(chǎng)景在圖像處理、OCR、智能文檔處理和NLP等方向需求。賽博智能學(xué)習(xí)平臺(tái)持續(xù)將AI大模型等前沿技術(shù)與行業(yè)數(shù)據(jù)深度結(jié)合,在技術(shù)與業(yè)務(wù)場(chǎng)景之間搭橋鋪路,讓AI技術(shù)快速在場(chǎng)景中落地,在應(yīng)用場(chǎng)景中產(chǎn)生價(jià)值,帶動(dòng)產(chǎn)業(yè)發(fā)展和升級(jí)。






