
EN
● 如何利用智能文檔處理(IDP)優化保險業理賠與運營流程?
● 告別手動錄單:OCR如何解決物流單據處理慢、錯、雜三大痛點?
你是否想過,如何將一沓厚厚的紙質文件,輕松變成可以在電腦上編輯、搜索的電子版?答案就是光學字符識別(Optical Character Recognition),簡稱OCR。
簡單來說,OCR就像一臺“數字化復印機”,但它做的遠不止復印。它能自動掃描文檔,并將掃描件轉換成機器可以讀取、編輯和分享的文件。舉個例子:當你用手機或掃描儀拍下一張購物小票時,電腦會存為一張圖片。這張圖片里的文字,你無法直接復制,也無法進行字數統計。但只要通過OCR工具處理,這張圖片就能“活”過來,變成一個包含所有文本信息的文檔,里面的文字可以隨意編輯。無論是相機拍攝的照片、純圖片的PDF,還是掃描件,OCR技術都能從中提取出數據,讓原本靜態的內容變得可操作,省去了人工錄入的繁瑣。

盡管我們生活在一個數字時代,但發票、合同、法律文件等紙質材料在許多商業活動中仍然普遍存在。這些“紙山”不僅占用大量物理空間,管理起來也費時費力。因此,“無紙化”正成為越來越多企業的選擇。
過去,將紙質文件掃描成圖片,依然需要耗費大量時間進行手動整理和信息錄入。如今,許多免費的OCR工具就能輕松解決這個問題。它們能將圖片中的文字轉換成可被其他商業軟件讀取的文本數據,為個人和企業節省大量時間和金錢。這項技術可以簡化操作流程、輔助數據分析、實現流程自動化,從而全面提升生產力。

OCR的工作過程,大致可以分為四個核心步驟:
1.圖像分析: 首先,掃描儀讀取文檔,將其轉化為計算機能理解的二進制數據。接著,OCR軟件會分析這個掃描文件,區分出淺色的背景區域和深色的文字區域。
2.預處理: 為了提升識別準確率,OCR技術會通過一系列技巧對圖像進行“美化”和修正:
a.平滑文字邊緣,去除圖像中的噪點。
b.校正掃描過程中可能出現的傾斜。
c.整理圖像中的線條和方框。
d.對于多語言OCR技術,還需要識別文檔所用的文字腳本。
3.文字識別: 這是最核心的一步,主要通過兩種方法實現——特征提取和模式匹配。
a.特征提取 (Feature extraction):系統不再進行像素級的硬性比對,而是分析字符的拓撲和幾何特征,例如直線、曲線、閉環、交叉點的數量和相對位置。例如,大寫字母“A”可以被描述為“由兩條斜線和一個橫線相交構成”。這種方法對字體的變化具有更強的魯棒性,是現代AI驅動OCR技術的基礎。
b.模式匹配 (Pattern matching): 這種方法會先分離出單個的字符圖像,我們稱之為“字形 (glyph)”,然后將其與一個預存的、標準字形的數據庫進行比對。對于字體統一、印刷清晰的文本,這種方法速度快、效果好。但其弱點也十分明顯:一旦遇到庫中沒有的新字體、藝術字或圖像質量不佳的字符,識別率會急劇下降
4.后處理: 當所有內容分析完畢后,系統會將提取出的文本數據轉換成一個正式的電子文件。一些OCR工具還能生成一個帶注釋的文件,讓你直觀地比較掃描件的原始樣貌和識別后的版本。如果在識別時遇到問題,通常需要檢查一下掃描件的質量是否足夠高,比如光線是否充足、圖像是否清晰、有沒有歪斜等。
這項改變文檔處理方式的技術,由發明家雷·庫茲韋爾 (Ray Kurzweil) 在1974年開發。他創立了庫茲韋爾計算機產品公司 (Kurzweil Computer Products, Inc.),其技術幾乎能識別任何印刷字體。庫茲韋爾認為,這項技術的最佳應用是為盲人制造一臺機器學習設備。于是,他發明了一臺能夠大聲朗讀文本的閱讀機,實現了從文本到語音的轉換。
1980年,他對將紙質文本商業化更感興趣的施樂公司 (Xerox) 收購了他的公司。
然而,OCR技術直到20世紀90年代初才開始普及,當時它被廣泛用于數字化歷史悠久的報紙。從那時起,OCR經歷了飛速發展。今天的OCR已經能夠實現近乎完美的轉換,并通過先進的方法實現文檔處理流程的自動化。在這項技術出現之前,人們必須手動重新打字錄入所有文檔,這不僅耗時耗力,也更容易出錯。如今,OCR已變得觸手可及,持續為個人和商業應用提升效率。
數據科學家根據應用場景,將OCR區分為幾種不同類型:
●簡單光學字符識別 (Simple OCR): 這種軟件將不同的字體和文本圖像模式存為模板。它通過模式匹配算法,逐個字符地在內部數據庫中進行比對。由于字體和手寫風格的數量近乎無限,這種方案有其局限性。
●智能字符識別 (Intelligent Character Recognition, ICR): 作為現代OCR技術的一部分,ICR像人類一樣“閱讀”文本。它利用機器學習軟件,讓機器像人一樣思考。一個被稱為“神經網絡”的系統會反復研究文本和處理圖像,通過分析線條、曲線、閉環等特征,并綜合不同層級的數據,最終得出識別結果。
●智能單詞識別 (Intelligent Word Recognition, IWR): 這項技術與ICR原理相似,但它研究的是整個單詞的圖像,而不是先將圖像預處理成單個字符。
●光學標記識別 (Optical Mark Recognition, OMR): 這種技術主要用于識別文檔中的水印、標志、Logo等特定標記。
以下是一些備受好評的OCR工具,無論個人用還是企業用都非常出色:
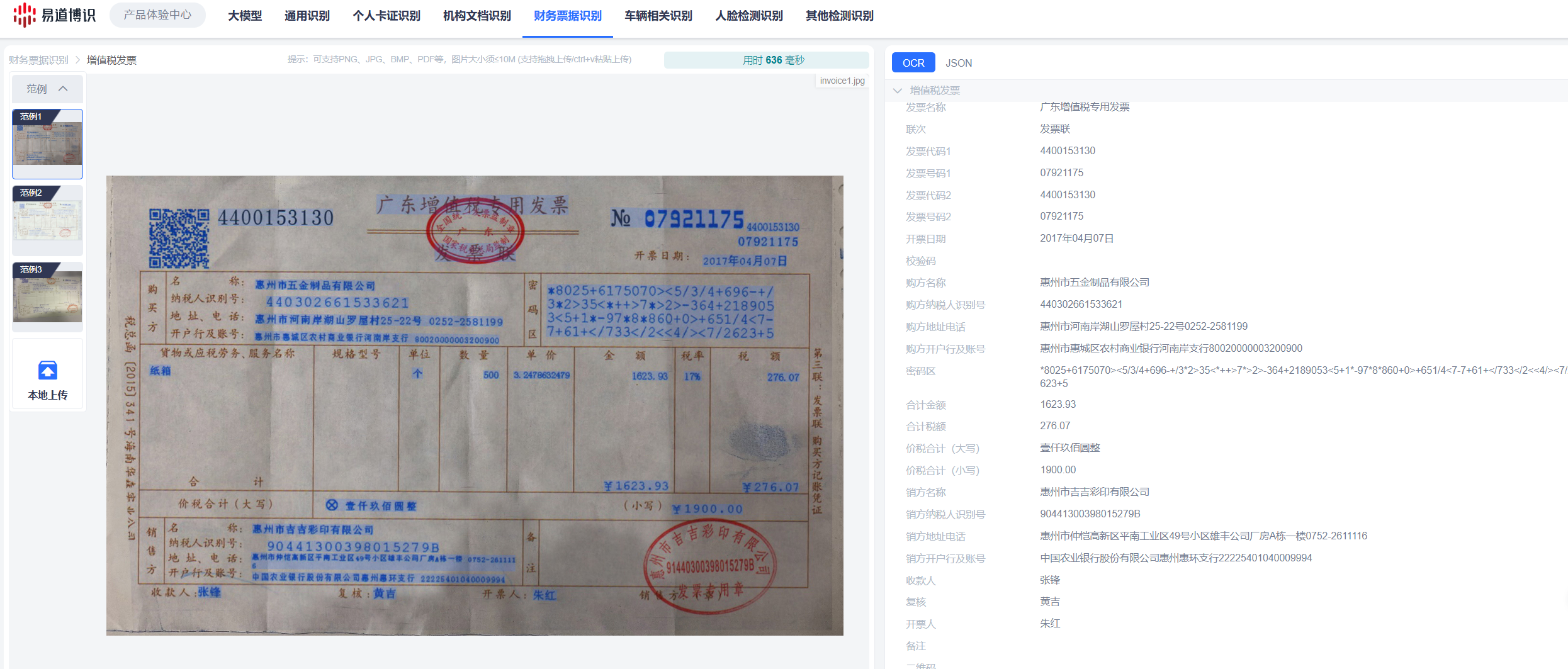
1.易道博識:提供7大類,60多種主流OCR識別場景,覆蓋主流識別需要,比如身份證、銀行卡、發票/報銷票據等,還支持財務報表識別、銀行流水單識別,文字識別精度超99.5%,非常適合企業的文檔OCR識別需求。
2.Adobe Acrobat Pro: 提供全面的OCR功能,可以極大地簡化工作流程。除了基本的OCR功能,你還可以對文檔添加注釋和反饋、比較兩個版本的差異,甚至有專門掃描表格的工具。它與免費的Adobe Scan應用配合默契,用手機掃描的文檔能自動識別文本。
3.OmniPage Ultimate: 以其極高的轉換準確度而聞名。它允許用戶創建自定義的工作流程,讓處理好的文檔自動以正確的格式發送到指定位置。
4.Abbyy FineReader: 一款強大的工具,能將紙質文檔轉換為PDF、Microsoft Office格式等多種數字格式。它支持批量處理大量文檔,并能識別多達192種語言。
5.Readiris: 支持多種文件格式,并可以為文檔添加簽名、安全保護、評論、水印和注釋。
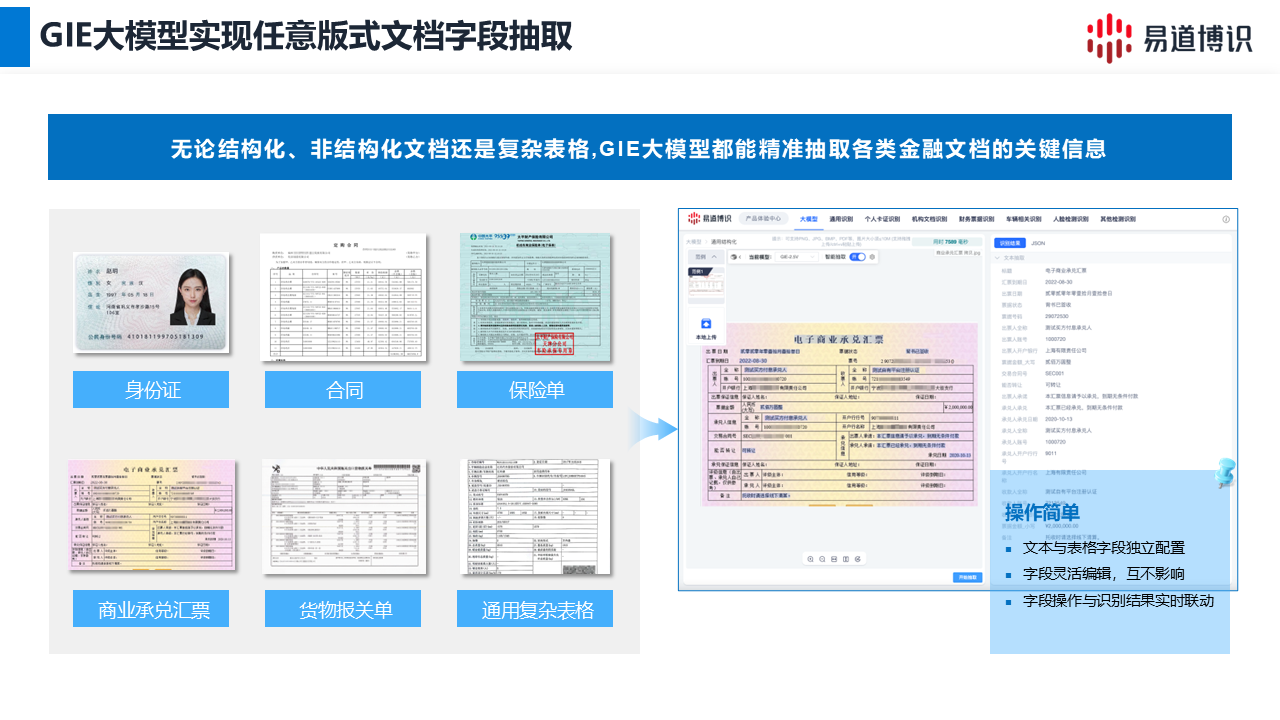
除了最常見的將印刷品轉換為可編輯文本外,OCR的應用場景十分廣泛:
●輔助功能: 幫助視障人士獲取信息。
●數據自動化: 自動從車牌、發票、護照等文件中提取數據,并錄入搜索引擎或數據庫。
●商業領域: 隨著業務增長,手動處理文檔變得不切實際。OCR通過自動化數據提取,將員工從繁瑣的數據錄入工作中解放出來,讓他們能專注于更重要的任務。數據數字化后,不僅降低了成本,也更集中、更安全,減少了丟失或被盜的風險。
●教育領域: OCR是學生的學習利器。它可以將紙質作業掃描成數字文檔,并通過朗讀功能幫助有閱讀障礙(如誦讀困難)的學生學習。學生還可以方便地調整文本顏色、大小,添加高亮和數字書簽。
●醫療領域: 醫療行業使用OCR來處理海量的病歷,如檢查報告、治療記錄和保險支付單。它簡化了病歷管理,縮短了數據錄入電子健康記錄(EHRs)的時間,并提高了準確性。醫生可以通過OCR快速搜索到患者的既往病史,藥方也可以被掃描以減少用藥錯誤。
在過去幾十年里,OCR和機器學習都取得了指數級的增長,未來只會更加智能。下一代OCR技術建立在人工智能和機器學習之上,早已超越了簡單的字符匹配。
結合最新的大模型,現在的OCR不僅能不僅能“看見”掃描的文本,更能“理解”文本的含義。隨著大模型技術的發展,這一趨勢將更加明顯。總而言之,通過將靜態的紙質文檔轉換為智能、可搜索的數字文檔,OCR技術減少了人工勞動、時間和成本,讓企業能夠為客戶和員工提供更高效、更便捷的信息獲取體驗。





