
EN

● 一文讀懂OCR識別:核心原理、歷史發(fā)展及OCR識別場景
● 如何利用智能文檔處理(IDP)優(yōu)化保險(xiǎn)業(yè)理賠與運(yùn)營流程?
● 告別人工錄入,OCR文字識別在銀行業(yè)務(wù)中的應(yīng)用
● 告別手動(dòng)錄單:OCR如何解決物流單據(jù)處理慢、錯(cuò)、雜三大痛點(diǎn)?
銀行每天堆積如山的紙質(zhì)文件,是怎么處理的?
在過去,這需要大量的人力,逐字逐句地錄入電腦。不僅慢,還容易出錯(cuò)。現(xiàn)在,情況完全不同了。使用OCR文字識別 (Optical Character Recognition)。它能快速讀取圖片、掃描件上的文字,并將其轉(zhuǎn)換成可編輯的電子數(shù)據(jù)。無論是簡單的圖片轉(zhuǎn)文字,還是復(fù)雜的報(bào)表識別,它都能勝任。
今天,我們就來看看OCR在銀行業(yè)務(wù)中的應(yīng)用。
1. 效率太低,等不起
在柜臺(tái)辦業(yè)務(wù),工作人員要把用戶的身份證、申請表、各種證明材料一個(gè)個(gè)手動(dòng)錄入系統(tǒng)。這個(gè)過程非常緩慢。如果遇到業(yè)務(wù)高峰期,排隊(duì)的隊(duì)伍能長得讓人絕望。后臺(tái)的錄單中心更是如此,成千上萬的會(huì)計(jì)憑證需要人工處理,一個(gè)環(huán)節(jié)卡住,整個(gè)流程就得停擺。
2. 容易出錯(cuò),風(fēng)險(xiǎn)高
是人,就會(huì)犯錯(cuò)。長時(shí)間重復(fù)錄入海量數(shù)據(jù),眼花繚亂、手指疲勞是常有的事。一個(gè)數(shù)字敲錯(cuò),一個(gè)名字錄偏,都可能導(dǎo)致嚴(yán)重的業(yè)務(wù)差錯(cuò),甚至引發(fā)合規(guī)風(fēng)險(xiǎn)。
為了減少錯(cuò)誤,銀行不得不采用“雙人錄入、雙人復(fù)核”的模式,但這又進(jìn)一步增加了人力成本。
3. 合規(guī)審查,壓力大
紙質(zhì)文件不僅容易出錯(cuò),還難以監(jiān)管。
一張發(fā)票是否重復(fù)報(bào)銷?一份簽名是否偽造?這些都需要依賴人工審核,很容易出現(xiàn)疏漏。
同時(shí),大量的紙質(zhì)資料在傳遞和保管過程中,還存在信息泄露的風(fēng)險(xiǎn),這讓銀行在反洗錢、實(shí)名制管理等方面承受著巨大的合規(guī)壓力。
4. 數(shù)據(jù)沉睡,難利用
更關(guān)鍵的是,海量的紙質(zhì)文件和影像資料,就像一座座“數(shù)據(jù)孤島”。這些數(shù)據(jù)沒有被結(jié)構(gòu)化,很難被系統(tǒng)檢索和分析。銀行坐擁金山,卻無法挖掘其價(jià)值,無法用于精準(zhǔn)營銷、風(fēng)險(xiǎn)評估和智能決策。
這些痛點(diǎn),嚴(yán)重制約了銀行的服務(wù)效率和發(fā)展空間,數(shù)字化轉(zhuǎn)型勢在必行。而OCR,正是解決這些問題的關(guān)鍵鑰匙。
過去開個(gè)銀行賬戶,必須本人帶著身份證跑到網(wǎng)點(diǎn)辦理。
現(xiàn)在,很多銀行都推出了線上開戶服務(wù),你只需要一部手機(jī),下載銀行的App,對著身份證拍張照上傳,它能瞬間讀取身份證上的姓名、號碼、地址等全部信息,并自動(dòng)填入申請表。
整個(gè)過程不到一分鐘,省去了跑腿的麻煩和排隊(duì)的煎熬。OCR技術(shù)還常常與人臉識別結(jié)合,確保是“人證合一”,既便捷又安全。
銀行每天都要處理海量的支票、匯票、回單等。傳統(tǒng)人工錄入一張憑證的關(guān)鍵信息,平均需要15秒。而OCR系統(tǒng)完成同樣的工作,只需要不到1秒。速度是人工的數(shù)十倍!機(jī)器不僅快,還不知疲倦,能7x24小時(shí)工作。這極大地釋放了柜面人力。

申請貸款,需要提交一大堆材料:收入證明、銀行流水、房產(chǎn)證……這些材料往往是圖片或PDF掃描件。信貸員過去需要手動(dòng)把這些PDF掃描件轉(zhuǎn)Word或錄入系統(tǒng),一個(gè)字一個(gè)字地核對,流程非常漫長。現(xiàn)在,OCR可以自動(dòng)批量處理這些文件。過去需要幾天的審核流程,現(xiàn)在可能幾個(gè)小時(shí)就能完成,大大縮短了放款周期。
銀行的合同又長又復(fù)雜,信貸合同、抵押合同、客戶協(xié)議……
人工錄入這些合同,不僅效率低下,還容易遺漏關(guān)鍵條款,埋下風(fēng)險(xiǎn)隱患。
OCR技術(shù)能直接掃描整個(gè)合同文本,自動(dòng)提取借款人、利率、還款計(jì)劃等核心要素,并存入系統(tǒng)。
更厲害的是,它還能進(jìn)行智能比對,快速發(fā)現(xiàn)多份合同之間的條款差異,或者找出不符合規(guī)范的內(nèi)容,成為合規(guī)審核的“火眼金睛”。
通用OCR技術(shù)解決了基礎(chǔ)問題,但金融業(yè)的需求遠(yuǎn)不止于此。
一方面,身份證、銀行卡這類標(biāo)準(zhǔn)化文檔,要求極致的速度和精度。另一方面,版式各異的合同、理賠資料,又需要極強(qiáng)的泛化處理能力。如何兼顧?在眾多服務(wù)商中,易道博識提出的“大小模型協(xié)同”新范式,給出了新的答案。
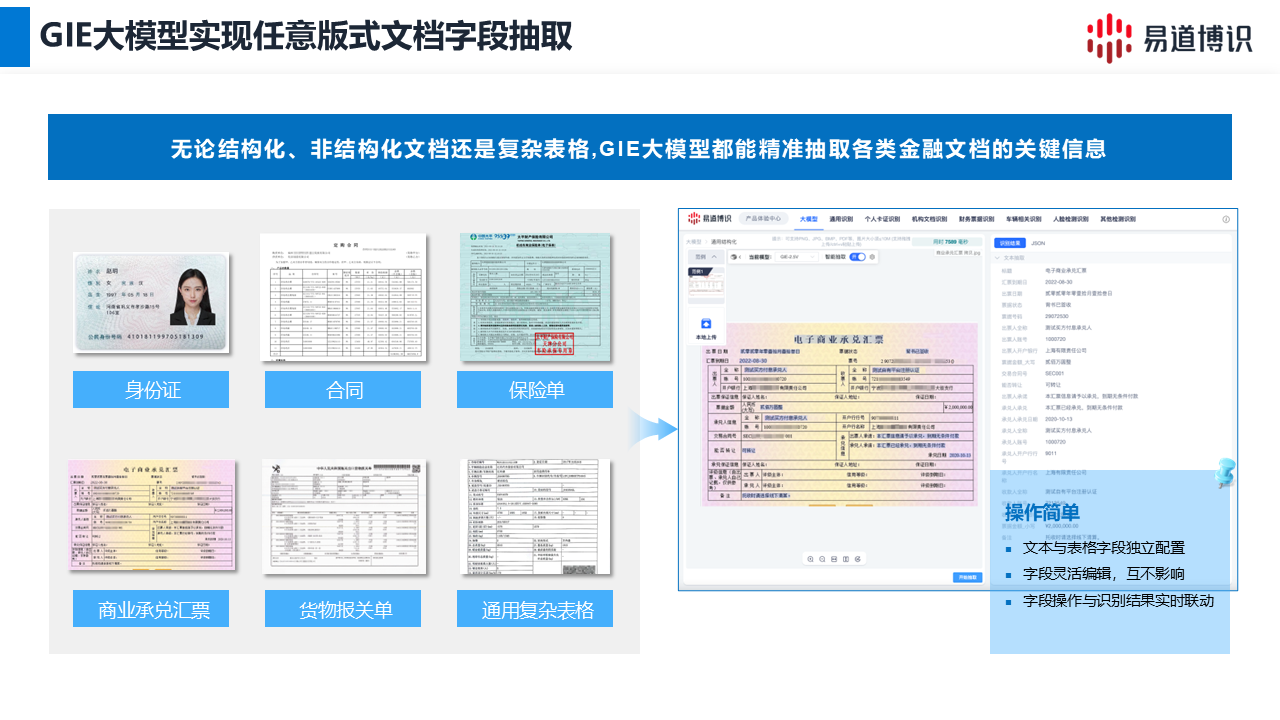
針對身份證、發(fā)票等高頻、標(biāo)準(zhǔn)化的文檔,易道博識采用深度優(yōu)化的“專用小模型”。
它的優(yōu)勢是什么?快!準(zhǔn)!識別速度低于300毫秒,快到肉眼無法感知。同時(shí),準(zhǔn)確率超過99.5%,為業(yè)務(wù)的穩(wěn)定運(yùn)行提供了堅(jiān)實(shí)保障。
為了滿足不同銀行的需求,它還支持私有化部署、提供移動(dòng)端SDK和云服務(wù)API等多種靈活的合作方式。
那遇到版式不固定的非標(biāo)文檔怎么辦?
比如一份全新的合同,傳統(tǒng)OCR技術(shù)可能就“懵了”,需要重新標(biāo)注數(shù)據(jù)、訓(xùn)練模型,耗時(shí)耗力。易道博識自研的GIE(通用信息抽取)大模型,它不再依賴固定的模板,而是能真正“理解”文檔的版式和語義。業(yè)務(wù)人員甚至不需要懂技術(shù),只需要輸入“提示詞”(Prompt),告訴模型要抽取哪些字段,就能快速配置好任務(wù)。
過去需要幾周甚至幾個(gè)月的開發(fā)周期,現(xiàn)在最快幾小時(shí)就能上線。這極大地提升了業(yè)務(wù)的敏捷性,降低了創(chuàng)新成本。
“大小模型協(xié)同”的優(yōu)勢,在于實(shí)現(xiàn)了資源的最優(yōu)配置。
用“小模型”處理高頻的標(biāo)準(zhǔn)化文檔,保證效率和低消耗。用“大模型”處理復(fù)雜的非標(biāo)文檔,提供強(qiáng)大的擴(kuò)展性。這樣的組合拳,既高效又經(jīng)濟(jì),顯著降低了銀行實(shí)現(xiàn)全面文檔智能化的技術(shù)門檻和成本。
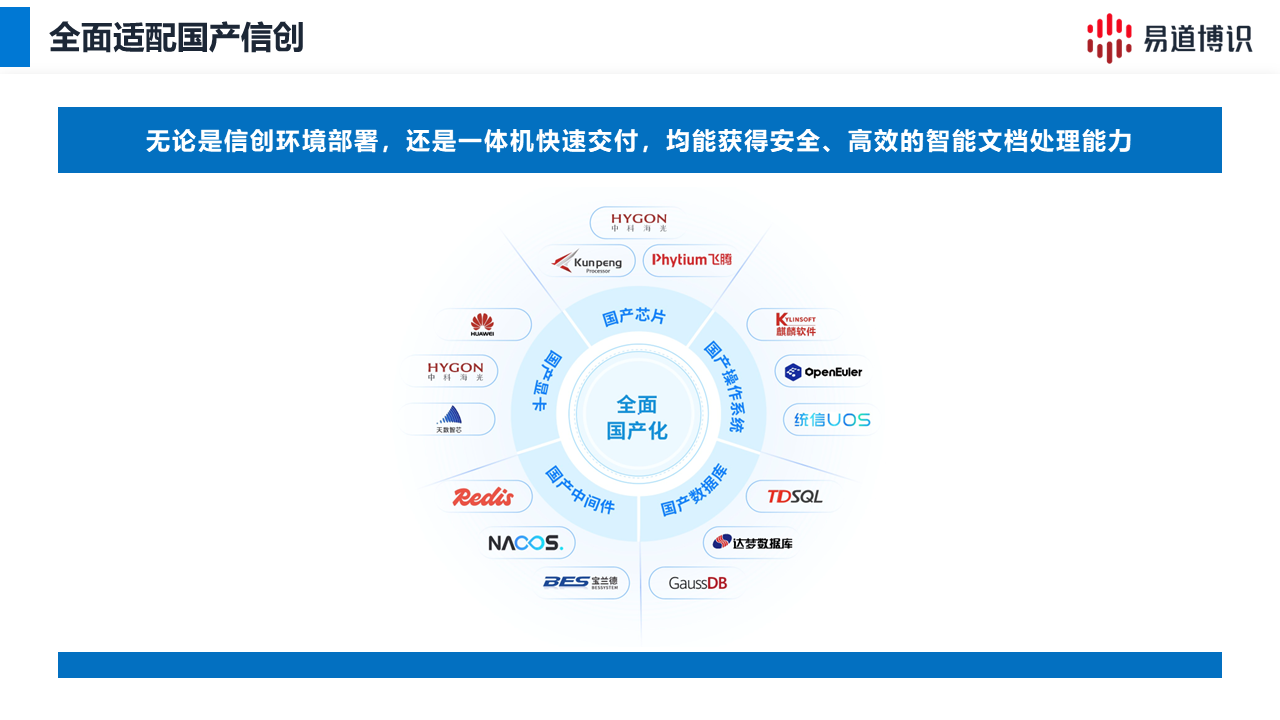
更關(guān)鍵的是,易道博識的整套方案已全面適配國產(chǎn)信創(chuàng)體系,能與主流國產(chǎn)芯片、服務(wù)器、操作系統(tǒng)無縫融合,確保了金融數(shù)據(jù)處理方案的高安全性和高可靠性。
未來的OCR將從“文字識別”進(jìn)化到“文檔理解”。它不僅認(rèn)識字,還能讀懂合同條款的深層含義,理解財(cái)務(wù)報(bào)表背后的經(jīng)營狀況。總而言之,OCR文字識別,完美解決了銀行在處理海量文檔時(shí)的效率、成本和風(fēng)控難題。從簡單的圖片轉(zhuǎn)文字,到以易道博識為代表的“大小模型協(xié)同”精細(xì)化方案,OCR正在為銀行業(yè)的數(shù)字化轉(zhuǎn)型注入源源不斷的動(dòng)力。




